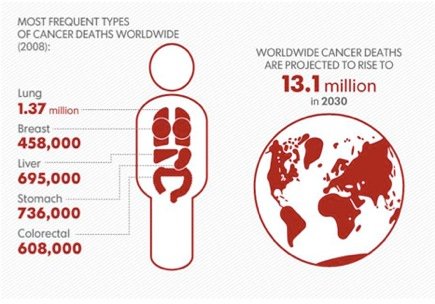
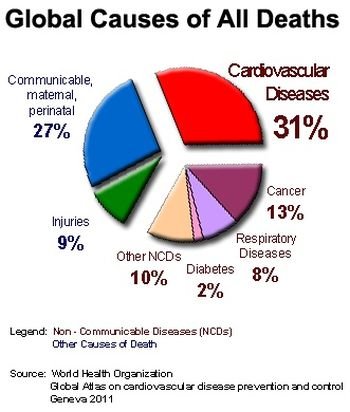
World Health Organization _ Cancer

Politics of cancer care
There are clearly many angles to the politics of cancer care, and these are linked closely to the economics of the disease. For the purposes of this chapter, I will focus on the differences in cases diagnosed and death rates and how they drive the politics of the disease, using breast and prostate cancer to illustrate gender differences and breast and lung cancer to illustrate social class effects.
In many ways, prostate cancer is the male counterpart of breast cancer. The similarities extend to a number of levels: both organs have a role in sexuality and reproduction; both change during life in response to hormone levels; both cancers can be treated by changes in the hormone environment; and treatments for the cancers arising in the respective organs cause profound changes in sexual function.
Politically, the powerful sexual and emotional imagery of the breast has been used to great effect to channel research and treatment funds into breast cancer for many decades. This has resulted in steady and progressive improvement in outcomes for women with breast cancer, reflected both in improved survival and reduced damage from successful treatment. For example, women are increasingly offered less mutilating surgery or breast reconstructions rather than radical mastectomy. On the drug funding issue, women have again been very effective at campaigning for new treatments – witness the rapid uptake of trastuzumab (better known as Herceptin) across the European and North American healthcare systems.
Until recently, despite the biological parallels, there was no analogous movement to support men with prostate cancer or campaigning to improve treatments and outcomes. As recently as 1995, for example, spending on prostate cancer research in the UK was only one-tenth that on breast cancer. In the last 10 years, this has changed, partly driven by the PSA test. This shifted the spectrum of prostate cancer substantially to the ‘left’, with a decrease in late cases and increase in early cases for which the treatment options are more varied and the possibility exists for cure or prolonged survival with the disease. This historical lack of public health and research interest is particularly surprising given the general concentration of political and economic power in the hands of men of middle age and above – those most at risk of the disease and with very little risk of breast cancer (though men can get it). The difference appears to be rooted in the differing psychologies of men and women – it’s fine for women to talk about breast cancer, and women are not seen as diminished but often rather strengthened by it – witness Kylie Minogue’s world tour. On the other hand, it has previously been very difficult for men to talk about the disease, particularly when treatments carry ‘unmacho’ risks such as impotence and incontinence, quite apart from the fundamentally embarrassing route needed for diagnosis (via the rectum). Coupled with most men’s general ‘ostrich’ approach to all matters related to health, the result has been a price paid by men living shorter, less healthy lives than women.
More recently, however, there has been a shift in public and economic policies, with more money spent on treatment for men and research into the disease. This has been driven no doubt in part by the pharmaceutical industry’s belated realization that there is a lot of money to be made from one of the biggest male cancer killers in the West. There has also been a change in that major public figures such as Colin Powell, Roger Moore, and Rudolph Giuliani have been prepared to talk about their treatment for the disease.
Finally, the issue of smoking and public policy is worth mentioning in the context of the politics of cancer care, as this has varied widely across the world and over the decades. Not too long ago, tobacco companies actually ran adverts with the strap-line that a particular cigarette was the preferred brand for doctors. The linkage of smoking to increased risk of various cancers has been one of the triumphs of epidemiological research, and has resulted in massive reductions in the rates of smoking and diseases linked to it in the developed world. A range of measures has driven this, from legal (smoking bans) through educational (advertising and sponsorship bans, health warnings) through to fiscal (tax the stuff, which has the additional benefit of paying for the healthcare needed to pick up the consequences for smokers). In the developing world, things are different, however: smoking is still seen as ‘cool’, underpinned by advertising and marketing to young people, rather than the pariah activity banished to chilly doorways it has increasingly become in Europe and North America.
Furthermore, the money brought in to developing countries by the big multinational tobacco companies carries with it much political clout, and this can used to tone down the public health assault on the habit that has occurred in the West. Coupled with the young age structures of developing countries, an epidemic of developing world smoking-related cancers – lung, bladder, throat, mouth – can be anticipated in the coming years. In countries like China which are rapidly modernizing and improving living standards and life expectancy, this can be expected to result in particularly large increases in these cancers.
How does cancer develop?
In order to understand how cancer develops, it is necessary to include a little background on basic cell biology. The cell is the basic building block that makes up all living things. The human body, in common with all animals from the smallest such as yeast to the largest blue whale, is composed of cells. Some animals – yeast, for example – are made of single cells; others, ourselves included, are made of many different sorts of cells – blood, bone, brain, kidney, and so on. All cells in an organism have their own carefully controlled life cycle. Cancer occurs when the control of this cycle goes wrong, leading to unregulated growth of a group of cells which can spread and damage other structures in the body. This chapter will focus on how cancer develops and also on some of the underlying biology needed to understand this. I will also illustrate how an understanding of the causes can be used to define treatment strategies.
The key component of the cell for understanding cancer is the nucleus, which holds the DNA that contains the genetic code. Cancer is caused fundamentally by damage to the DNA leading to abnormal, unregulated growth of cells. Remarkably, although different cells may differ markedly in their appearance and function (for example, nerve cells, muscle cells, and blood cells), all the cells in a given organism share the same DNA code. DNA is clustered into long strands called chromosomes. There are 23 pairs in each human cell. Within each chromosome, the DNA is arranged in genes, each one coding for a single protein. We can think about genes and chromosomes as being like a library of books, with each of the 23 chromosomes an individual volume and each of the 21,000 genes a page of instructions in that volume. It is easy to see conceptually how damage to a page of instructions can lead to alterations in the properties of a cell.
We will run through how these different structures work and interact, and how they can go wrong to lead to the development of a cancer. Everyone starts life as a single fertilized egg that develops first into a ball of identical cells and then, progressively, grows, organizes, and develops into a complete complex individual. The process by which cells develop from this initial group into highly specialized subtypes is one of the most incredibly complex processes in nature and yet is happening constantly all around us and within us.
This clearly requires an intricate network of checks and balances. It requires that cells communicate with their neighbours to ensure that the right development path is followed at the right time. It requires that cells no longer required are deleted and eliminated with the minimum of disruption (a process called apoptosis, from the Greek word meaning ‘a falling off of petals’). As organs develop, they must grow their own blood supplies and maintain them in response to damage. It requires that organ systems communicate with each other, for example nerves connecting with the muscles they control. Endocrine (hormone) glands are coordinated to produce their products in cycles (for example, the ovaries) or in response to stress (the adrenal glands). This is achieved by genes being switched on and off in a coordinated fashion as individual organ systems grow and develop. Once the growth process is complete and the animal is formed, tissues must be maintained, damage repaired, and general housekeeping kept ticking over – nutrients supplied and processed, waste products eliminated, and so on. The more one thinks about the mind-blowing complexity of all these tasks, the remarkable thing is that the processes run so reliably for so many years in most people, and that cancer – essentially, unregulated cell division – does not occur more frequently than it does.
DNA structure and function
As already mentioned, the genetic code is stored in human cells in 23 pairs of chromosomes. Each chromosome comprises a very long molecule of DNA containing the genes, which are interspersed with spacer sequences. Each gene is flanked by regions of DNA that control when a particular gene is switched on or off. For example, the gene coding for the protein myosin, a key component of muscle cells, will be switched on where needed – in muscle – but off in other tissues where it is not required, such as nerve cells. The network of on and off switches is clearly critical to regulation of the behaviour of cells, and study of these controls is a major feature of cancer research – if the controls do not work, cells can grow in an unregulated fashion, as occurs in cancers.
To understand how cells carry out all these functions, it is necessary to understand a bit more about the structure of DNA and how the code embedded in the DNA molecule is translated into the end product that is the functioning organism. DNA is an abbreviation for deoxyribose nucleic acid. It had been known for some time before the famous discovery of its double helical structure by Crick and Watson in 1953 that DNA contained the genetic code. The DNA molecule is a long spine of two alternating building blocks – a sugar (called deoxyribose) and a phosphate group linked to four molecules named adenine, guanine, cytosine, and thymine (abbreviated to A, G, C, T) and referred to as bases. These bases are arranged along the spine of the DNA molecule and form two complementary pairs, A with T and C with G, that can bond to each other. The double helical nature of DNA results from one strand (the positive or sense strand) being matched by a complementary antisense strand with an A paired with every T, C with every G, and so on. The A-T and C-G bonds thus provide the ‘glue’ that maintains the double helical structure of the DNA strands. The complementary nature of the bond process means that if the two strands are pulled apart and each used as a template for two new strands, the result is two identical copies of the first DNA molecule.
This inherent property of DNA, whereby it can make identical copies of itself, is one of the fundamental properties of all life on Earth. The structure of DNA is very tightly conserved across the whole spectrum from the simplest to the most complex. The fidelity of the duplication process is also extremely high. The error rate is so low that it takes many generations to accumulate significant differences – the rate of genetic ‘drift’ – and is one of the bases for evolutionary biology. Coming back to the genetic books in the library: each time a cell divides, a complete set of the 23 pairs of volumes with their 21,000 genes (‘pages’ of information) must be ‘typed’ by the cell. From time to time, a comma, letter, or full stop will be mistyped. Mostly, as in a book, this will not alter the meaning, but sometimes, changes will be critical, with consequent alteration to how the daughter cell carrying the change (called a mutation) functions. Parenthetically, the number of small random differences can be tracked across the evolutionary tree to allow estimates of when a given pair of species diverged from each other.
Genes and control of gene expression
The fundamental unit that the DNA is organized around is the gene. A gene contains the code for a single protein. Proteins can have many functions ranging from structural, for example a protein called tubulin which makes the cell’s internal ‘skeleton’, to functional, such as forming the parts of muscles that contract. This flow of information, whereby information in DNA is transcribed into a message (in RNA) and then into a single protein, is one of the central concepts of biology.
Proteins are the key building blocks of cells, responsible for all the key activities. Other components of cells, such as fats and sugars, are manufactured as a result of actions of proteins. Proteins clearly have to have a range of functions, therefore. These include: signaling both within and between cells; structure (a sort of microscopic scaffolding); and, very importantly, proteins called enzymes, which act on other biological molecules to bring about the formation of new molecules. This process can be destructive – for example, the enzymes in digestive secretions (and washing powders!) which break down food; or constructive – the enzymes involved in the manufacture of new molecules for the cell.
The production of a protein from a gene involves the transcription of the gene into a messenger ribose nucleic acid (mRNA) molecule within the nucleus of the cell. The RNA molecule has a structure like DNA but differs in key respects. Firstly, the deoxyribose sugar (the D in DNA) in the backbone is replaced by ribose (the R in RNA). Secondly, the molecule is single-stranded. And thirdly, the thymine (T) base is substituted by uracil (U), though the pairing remains the same. In order to make RNA, the DNA double helix is temporarily ‘unzipped’ into two single strands. A complementary RNA molecule then assembles and is transported out of the nucleus into the cytoplasm and the DNA then zips itself back up again. This process, another key part of biology, is called transcription.
Once in the cytoplasm, this messenger RNA must be converted into protein, the second key part of the translation of the code embedded in the DNA into functional proteins. A second sort of RNA – called transfer RNA – provides the link between the messenger RNA and the building blocks of protein. Key to this translation process is the triplet code embedded in the DNA. Proteins, like DNA, are made up of chains of simpler molecules. The protein building blocks, called amino acids, can be linked together to form effectively endless chains. The basic amino acid molecule has three key features – termed a carboxy terminus and an amino (hence the name) terminus, plus a variable side branch which gives each amino acid its distinct properties.
Transcription
Whilst in theory an infinite number of types of amino acids are possible, only 20 are found in living organisms. The DNA code is arranged in triplets called codons. There are 64 possible three-letter codes using A, T/U, C, and G. Each triplet has a specific meaning and can either refer to an amino acid or, in effect, form a punctuation mark. For example, within this coding system, AUG means ‘start here’ (termed a ‘start codon’); UAG, UGA, and UAA mean ‘stop here’; while the remainder are linked to specific amino acids – for example, cysteine is UGU or UGC. As there are 64 possible combinations in the triple code but only 20 amino acids, it follows that some amino acids have more than one triplet code. It can easily be seen, therefore, that a mutation which changes a single base can fundamentally alter the resultant protein. For example, a change from UGC (cysteine) to UGA (the stop signal) will shorten the resultant protein, with a possible major change in function.
Amino acids and protein structure
As already mentioned, the core code of the gene is flanked by complex regulatory machinery to ensure genes are switched on and off at the correct times. It is this regulation of gene function that is often faulty in the cancer cell.
Regulation of gene expression requires the interaction of a complex series of events. To understand this, a little more detail on gene structure is required. On both sides of the coding portion of a gene are the control regions. As with a mutation in the coding region described already, it can easily be understood how changes to the regulation of the gene or the processing of the messenger RNA can result in over- or under-production of a protein or the generation of an abnormal protein with undesirable properties. These control regions are themselves regulated by other genes, called transcription factors, which turn gene expression up or down like a volume control. The transcription factors are the key regulators of the whole process, and it is therefore unsurprising that many of the genes involved in cancer turn out to be from this family of proteins.
The hallmarks of cancer
Having covered the basics of the machinery, we can now turn to the ways in which the processes go wrong to produce a cancer. In 2000, two leading cell biologists, Douglas Hanahan and Robert Weinberg, published a seminal paper entitled ‘The Hallmarks of Cancer’ summarizing the changes that are both necessary and sufficient to produce a cancer. A cancer cell differs from normal cells in that it divides in an unregulated fashion. In addition, cancer cells have the ability to spread to and invade other parts of the body. Hanahan and Weinberg summarized the processes that must occur in the cell in order for it to be transformed from a normal, law-abiding member of cellular society into a dangerous outlaw. These changes are characterized as:
Self-sufficiency in positive growth signals;
Lack of response to inhibitory signals;
Failure to undergo ‘programmed cell death’ to eliminate faulty cells;
Evasion of destruction by the immune system;
The ability to grow in and destructively invade other tissues;
Ability to sustain growth by generating new blood vessels.
The first two of these are reasonably self-explanatory and lead to unregulated growth. The third is less obvious and is linked to the development process. If all cells simply grew and divided, it would not be possible, for example, to form hollow tubular structures such as the gut or blood vessels. To do this, certain cells must be deleted from the growing organism as the needs of the growing structure dictate.
This process, already mentioned, is called apoptosis, and is a key cellular function. Apoptosis is also a method that the organism uses to get rid of faulty or malfunctioning cells such as those nearing the end of their lifespan that need replacing. Cancer cells are by definition abnormal and thus should be self-deleting. Failure to undergo apoptosis is thus key to the transformation from an abnormal cell into one with limitless replicative potential. A further feature of apoptosis is that cells damaged by chemotherapy or radiotherapy are frequently not killed outright, but merely ‘mortally wounded’. The subsequent death of the cell is often by apoptosis, illustrating that the evasion mechanism is not completely shut down, even in the cancer cell. Increasing resistance to apoptosis is, however, one way in which the cancer cell evades destruction by chemotherapy or radiotherapy.
Understanding apoptosis is unsurprisingly therefore one of the major areas of cancer research.
Further distinguishing features of cancers are their ability to grow and to invade other tissues in the body while avoiding destruction themselves by the immune system. The immune system can be regarded as a sort of cellular police force that identifies intruders such as bacteria and eliminates them. As cancer cells are abnormal, the immune system should be able to identify and destroy them.
Evasion of this process is therefore essential to the cancer. As already indicated, the growth and development of cells, tissues, and organs is very finely regulated to ensure the correct sort of cell grows in the correct place and time in the organism. One key aspect of cancer growth is the acquisition of the ability to grow in the wrong place, and this is a feature that distinguishes a malignant tumour from a benign one, which can grow but not spread or invade. It should be noted that benign tumours can still present severe consequences, for example an acoustic neuroma is a benign tumour of the auditory nerve that transmits signals from the inner ear to the brain. The tumour will progressively enlarge, causing deafness and balance problems, without ever spreading elsewhere.
The final hallmark of cancer is the ability to grow a new blood supply. Any collection of cells larger than around one-tenth of a millimetre across needs a blood supply. As the new tumour grows, it must therefore acquire the ability to stimulate blood vessel growth. The blood vessel growth of tumours is often haphazard and turns out to use genes not involved in the maintenance of normal blood vessels.
The process is known as tumour angiogenesis, and because it differs from normal angiogenesis, it has become an important target for cancer drug development. If it is possible to knock out the blood supply of the cancer, further growth is prevented. One of the most successful of the new generation of targeted molecular therapies, bevacizumab (Avastin), works by targeting this process.

{kind=link}